Z-Ordering Support
Contents
Z-Ordering Support#
To improve query speed, Kyuubi supports Z-Ordering to optimize the layout of data stored in all kind of storage with various data format.
Please check our benchmark report here.
Introduction#
The following picture shows the workflow of z-order.
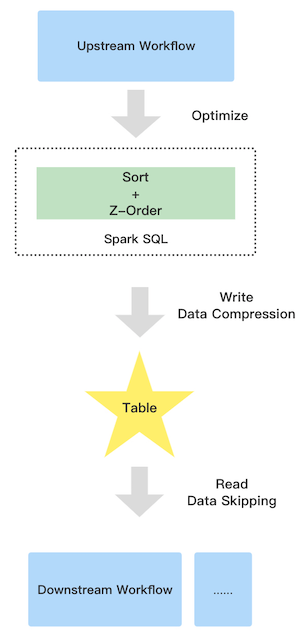
It contains three parties:
Upstream
Due to the extra sort, the upstream job will run a little slower than before
Table
Z-order has the good data clustering, so the compression ratio can be improved
Downstream
Improve the downstream read performance benefit from data skipping. Since the parquet and orc file support collect data statistic automatically when you write data e.g. minimum and maximum values, the good data clustering let the pushed down filter more efficient
Supported table format#
| Table Format | Supported |
|---|---|
| parquet | Y |
| orc | Y |
| json | N |
| csv | N |
| text | N |
Supported column data type#
| Column Data Type | Supported |
|---|---|
| byte | Y |
| short | Y |
| int | Y |
| long | Y |
| float | Y |
| double | Y |
| boolean | Y |
| string | Y |
| decimal | Y |
| date | Y |
| timestamp | Y |
| array | N |
| map | N |
| struct | N |
| udt | N |
How to use#
This feature is inside Kyuubi extension, so you should apply the extension to Spark by following steps.
add extension jar:
copy $KYUUBI_HOME/extension/kyuubi-extension-spark-3-1* $SPARK_HOME/jars/add config into
spark-defaults.conf:spark.sql.extensions=org.apache.kyuubi.sql.KyuubiSparkSQLExtension
Due to the extension, z-order only works with Spark-3.1 and higher version.
Optimize history data#
If you want to optimize the history data of a table, the OPTIMIZE ... syntax is good to go. Due to Spark SQL doesn’t support read and overwrite same datasource table, the syntax can only support to optimize Hive table.
Syntax#
OPTIMIZE table_name [WHERE predicate] ZORDER BY col_name1 [, ...]
Note that, the predicate only supports partition spec.
Examples#
OPTIMIZE t1 ZORDER BY c3;
OPTIMIZE t1 ZORDER BY c1,c2;
OPTIMIZE t1 WHERE day = '2021-12-01' ZORDER BY c1,c2;
Optimize incremental data#
Kyuubi supports optimize a table automatically for incremental data. e.g., time partitioned table. The only things you need to do is adding Kyuubi properties into the target table properties:
ALTER TABLE t1 SET TBLPROPERTIES('kyuubi.zorder.enabled'='true','kyuubi.zorder.cols'='c1,c2');
the key
kyuubi.zorder.enableddecide if the table allows Kyuubi to optimize by z-order.the key
kyuubi.zorder.colsdecide which columns are used to optimize by z-order.
Kyuubi will detect the properties and optimize SQL using z-order during SQL compilation, so you can enjoy z-order with all writing table command like:
INSERT INTO TABLE t1 PARTITION() ...;
INSERT OVERWRITE TABLE t1 PARTITION() ...;
CREATE TABLE t1 AS SELECT ...;