Solution for Big Result Sets
Solution for Big Result Sets#
Typically, when a user submits a SELECT query to Spark SQL engine, the Driver calls collect to trigger calculation and
collect the entire data set of all tasks(a.k.a. partitions of an RDD), after all partitions data arrived, then the
client pulls the result set from the Driver through the Kyuubi Server in small batch.
Therefore, the bottleneck is the Spark Driver for a query with a big result set. To avoid OOM, Spark has a configuration
spark.driver.maxResultSize which default is 1g, you should enlarge it as well as spark.driver.memory if your
query has result set in several GB. But what if the result set size is dozens GB or event hundreds GB? It would be best
if you have incremental collection mode.
Incremental collection#
Since v1.4.0-incubating, Kyuubi supports incremental collection mode, it is a solution for big result sets. This feature
is disabled in default, you can turn on it by setting the configuration kyuubi.operation.incremental.collect to true.
The incremental collection changes the gather method from collect to toLocalIterator. toLocalIterator is a Spark
action that sequentially submits Jobs to retrieve partitions. As each partition is retrieved, the client through pulls
the result set from the Driver through the Kyuubi Server streamingly. It reduces the Driver memory significantly from
the size of the complete result set to the maximum partition.
The incremental collection is not the silver bullet, you should turn it on carefully, because it can significantly hurt performance. And even in incremental collection mode, when multiple queries execute concurrently, each query still requires one partition of data in Driver memory. Therefore, it is still important to control the number of concurrent queries to avoid OOM.
Use in single connections#
As above explains, the incremental collection mode is not suitable for common query sense, you can enable incremental collection mode for specific queries by using
beeline -u 'jdbc:hive2://kyuubi:10009/?spark.driver.maxResultSize=8g;spark.driver.memory=12g#kyuubi.engine.share.level=CONNECTION;kyuubi.operation.incremental.collect=true' \
--incremental=true \
-f big_result_query.sql
--incremental=true is required for beeline client, otherwise, the entire result sets is fetched and buffered before
being displayed, which may cause client side OOM.
Change incremental collection mode in session#
The configuration kyuubi.operation.incremental.collect can also be changed using SET in session.
~ beeline -u 'jdbc:hive2://localhost:10009'
Connected to: Apache Kyuubi (Incubating) (version 1.5.0-SNAPSHOT)
0: jdbc:hive2://localhost:10009/> set kyuubi.operation.incremental.collect=true;
+---------------------------------------+--------+
| key | value |
+---------------------------------------+--------+
| kyuubi.operation.incremental.collect | true |
+---------------------------------------+--------+
1 row selected (0.039 seconds)
0: jdbc:hive2://localhost:10009/> select /*+ REPARTITION(5) */ * from range(1, 10);
+-----+
| id |
+-----+
| 2 |
| 6 |
| 7 |
| 0 |
| 5 |
| 3 |
| 4 |
| 1 |
| 8 |
| 9 |
+-----+
10 rows selected (1.929 seconds)
0: jdbc:hive2://localhost:10009/> set kyuubi.operation.incremental.collect=false;
+---------------------------------------+--------+
| key | value |
+---------------------------------------+--------+
| kyuubi.operation.incremental.collect | false |
+---------------------------------------+--------+
1 row selected (0.027 seconds)
0: jdbc:hive2://localhost:10009/> select /*+ REPARTITION(5) */ * from range(1, 10);
+-----+
| id |
+-----+
| 2 |
| 6 |
| 7 |
| 0 |
| 5 |
| 3 |
| 4 |
| 1 |
| 8 |
| 9 |
+-----+
10 rows selected (0.128 seconds)
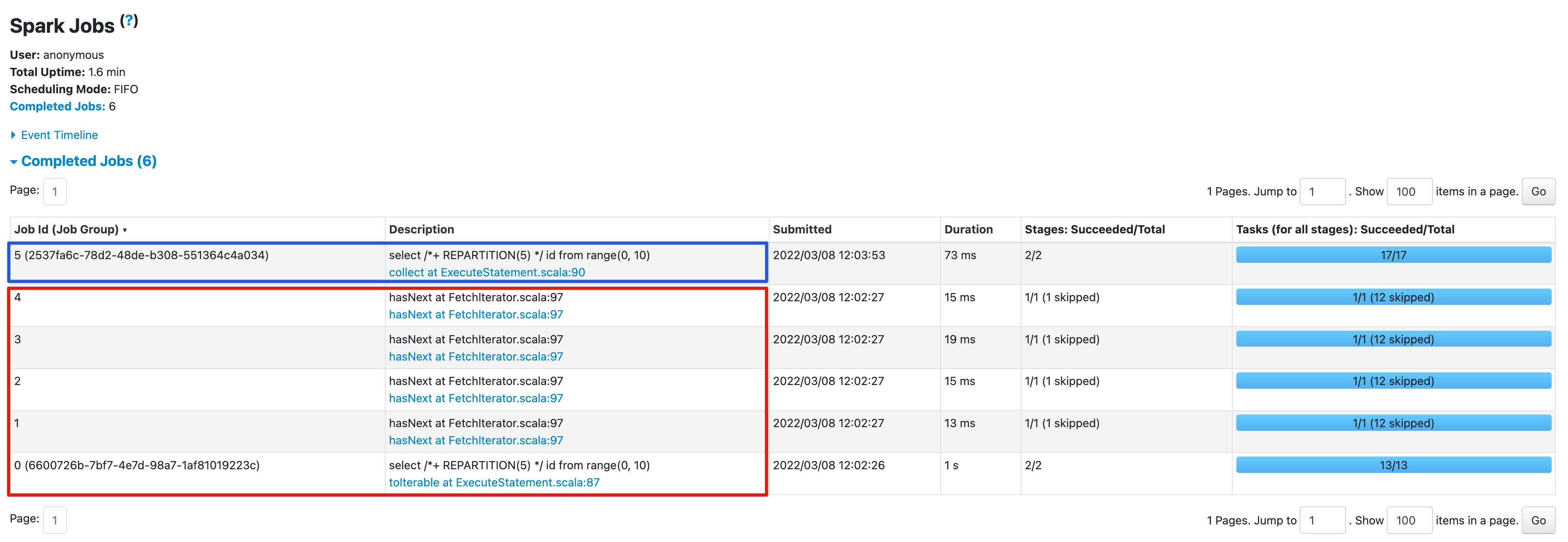
From the Spark UI, we can see that in incremental collection mode, the query produces 5 jobs (in red square), and in normal mode, only produces 1 job (in blue square).