Welcome to Kyuubi’s documentation!¶
Kyuubi™ is a unified multi-tenant JDBC interface for large-scale data processing and analytics, built on top of Apache Spark™.
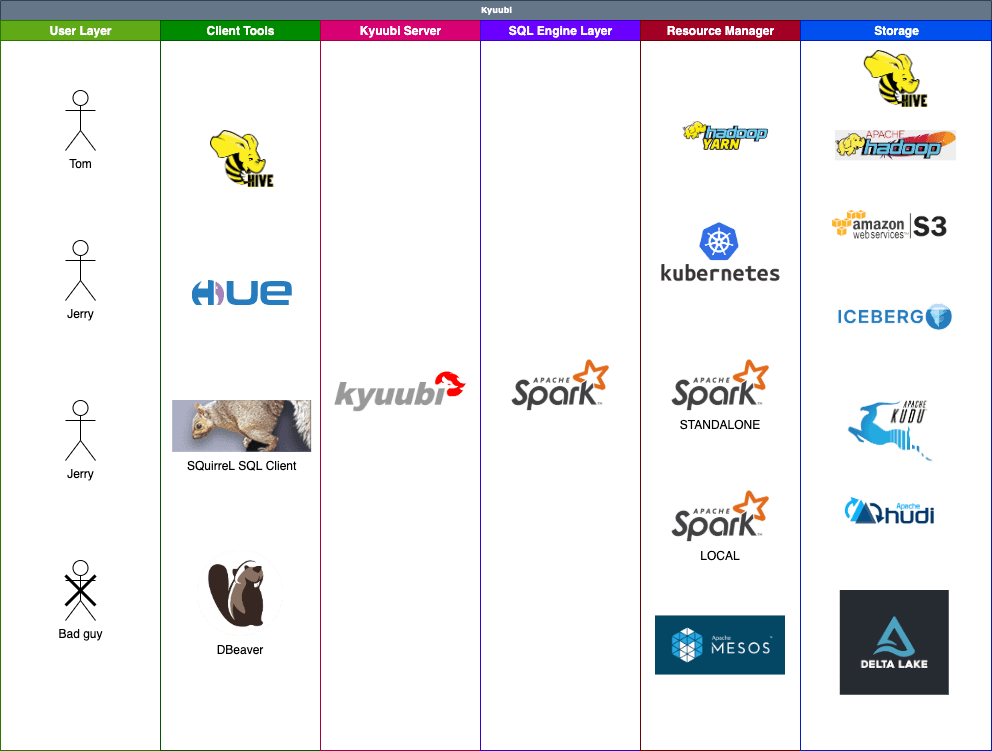
In general, the complete ecosystem of Kyuubi falls into the hierarchies shown in the above figure, with each layer loosely coupled to the other.
For example, you can use Kyuubi, Spark and Apache Iceberg to build and manage Data Lake with pure SQL for both data processing e.g. ETL, and analytics e.g. BI. All workloads can be done on one platform, using one copy of data, with one SQL interface.
Kyuubi provides the following features:
Multi-tenancy¶
Kyuubi supports the end-to-end multi-tenancy, and this is why we want to create this project despite that the Spark Thrift JDBC/ODBC server already exists.
Supports multi-client concurrency and authentication
Supports one Spark application per account(SPA).
Supports QUEUE/NAMESPACE Access Control Lists (ACL)
Supports metadata & data Access Control Lists
Users who have valid accounts could use all kinds of client tools, e.g. Hive Beeline, HUE, DBeaver, SQuirreL SQL Client, etc, to operate with Kyuubi server concurrently.
The SPA policy makes sure 1) a user account can only get computing resource with managed ACLs, e.g. Queue Access Control Lists, from cluster managers, e.g. Apache Hadoop YARN, Kubernetes (K8s) to create the Spark application; 2) a user account can only access data and metadata from a storage system, e.g. Apache Hadoop HDFS, with permissions.
Ease of Use¶
You only need to be familiar with Structured Query Language (SQL) and Java Database Connectivity (JDBC) to handle massive data. It helps you focus on the design and implementation of your business system.
Run Anywhere¶
Kyuubi can submit Spark applications to all supported cluster managers, including YARN, Mesos, Kubernetes, Standalone, and local.
The SPA policy also make it possible for you to launch different applications against different cluster managers.
High Performance¶
Kyuubi is built on the Apache Spark, a lightning-fast unified analytics engine.
Concurrent execution: multiple Spark applications work together
Quick response: long-running Spark applications without startup cost
Optimal execution plan: fully supports Spark SQL Catalyst Optimizer,
Authentication & Authorization¶
With strong authentication and fine-grained column/row level authorization, Kyuubi keeps your system and data secure.
High Availability¶
Kyuubi provides both high availability and load balancing solutions based on Zookeeper.
Usage Guide
Kyuubi Insider
Contributing
Appendix